Convert the Himalayan Database to SQLite

The Himalayan Database is a record of expeditions in the Nepalese Himalaya and a unique source of knowledge about the history of Himalayan mountaineering. The database is based on the expedition archives of Elizabeth Hawley, a longtime journalist based in Kathmandu, and it is supplemented by information gathered from books, alpine journals, and correspondence with Himalayan climbers. The records go back to 1903.
The database was maintained by the legendary Elizabeth Hawley in Kathmandu until her retirement. If you are interested in more details about the fascinating life of Elizabeth Hawley, I recommend the book I'll Call You in Kathmandu: The Elizabeth Hawley Story from Bernadette McDonald about the early days of Himalayan expeditions and her life in Kathmandu.
In 2017, a new non-profit organization (The Himalayan Database) was established to continue the work of Elizabeth Hawley, who retired in 2016. Elizabeth's long-term assistant Billi Bierling has taken over the role of Managing Director and continues to maintain and update the database with a team of record collectors in Kathmandu and around the world. As a result, version 2 of the Himalayan Database has now been released to the general public at no charge via internet download.
The Himalayan Database is a FoxPro application developed and maintained by Richard Salisbury, who worked as a computer programmer at the University of Michigan and traveled to Nepal more than 50 times for trekking and expeditions. In 1991, after meeting Elizabeth Hawley, they started to digitize Elizabeth's notes and created the first version of the Himalayan Database.
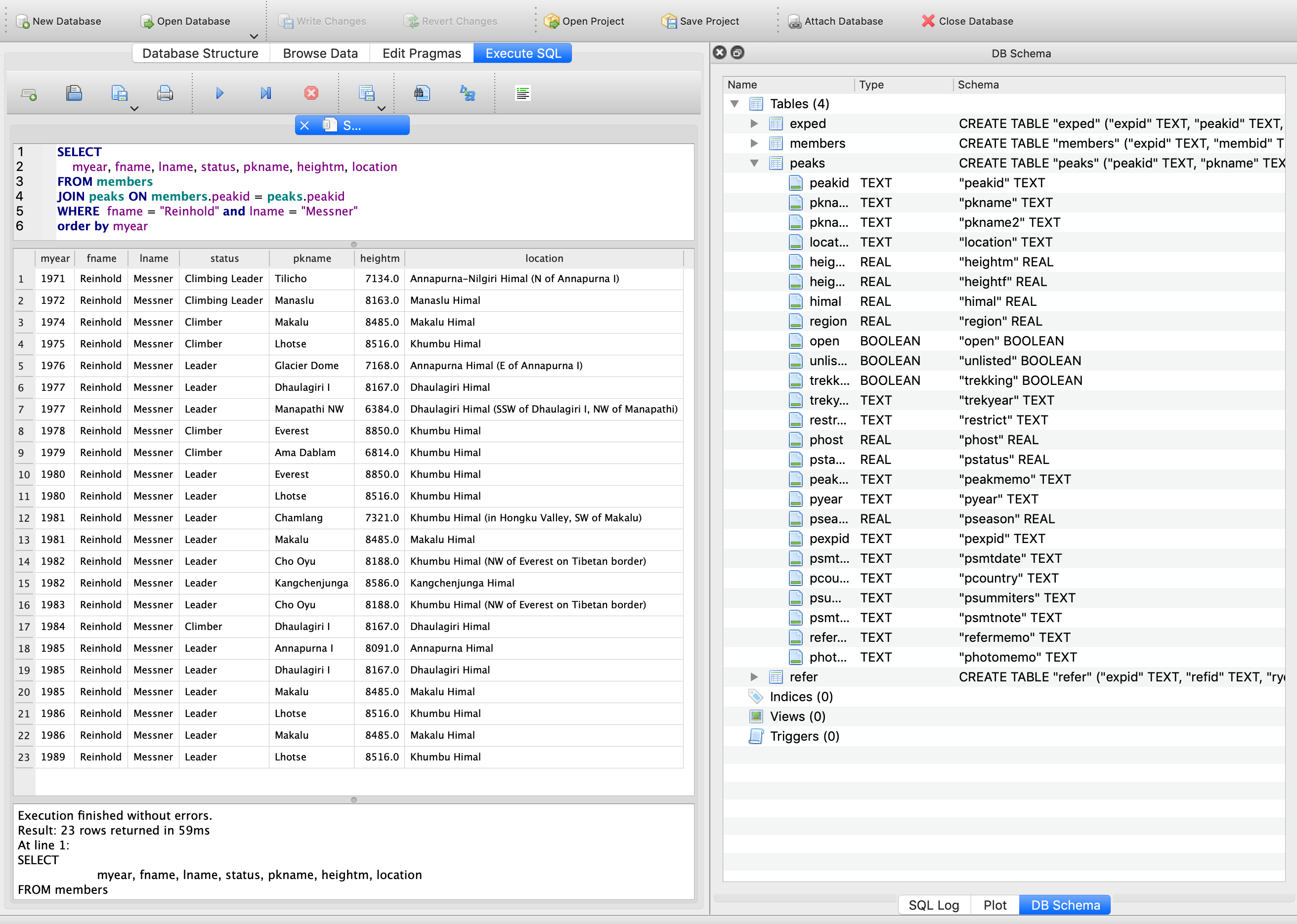
While documentation is available on how to run the FoxPro application with crossover on macOS, I was more interested in directly querying the contents from Python, so I wrote a small tool to convert it to a SQLite database.
The current Himalayan Database (version 2.3 with Autumn 2019–Winter 2019–Spring 2020 update) can be downloaded from the Himalayan Database download page.
$ mkdir download
$ wget https://www.himalayandatabase.com/downloads/Himalayan%20Database.zip -O download/Himalayan_Database.zip
$ unzip download/Himalayan_Database.zip -d download/
The zip file includes the application to run the FoxPro version, and the HIMDATA folder includes the necessary database .DBF files.
$ tree download/Himalayan\ Database/
download/Himalayan\ Database/
├── HIMDATA
│ ├── FILTERS.FPT
│ ├── SETUP.DBF
│ ├── exped.CDX
│ ├── exped.DBF
│ ├── exped.FPT
│ ├── filters.CDX
│ ├── filters.DBF
│ ├── members.CDX
│ ├── members.DBF
│ ├── members.FPT
│ ├── peaks.CDX
│ ├── peaks.DBF
│ ├── peaks.FPT
│ ├── refer.CDX
│ ├── refer.DBF
│ └── refer.FPT
├── Himal\ 2.3.exe
├── MSVCR71.DLL
├── VFP9R.DLL
└── VFP9RENU.DLL
The following script uses the Python library dbfread to access the DBF file format and convert it to a more convenient SQLite database. To run the script, install it with pip install dbfread in your virtual environment.
#!/usr/bin/env python
import sqlite3
from dbfread import DBF
def get_fields(table):
"""Get the fields and SQLite types for a DBF table."""
typemap = {
"F": "FLOAT",
"L": "BOOLEAN",
"I": "INTEGER",
"C": "TEXT",
"N": "REAL", # because it can be integer or float
"M": "TEXT",
"D": "DATE",
"T": "DATETIME",
"0": "INTEGER",
}
fields = {}
for f in table.fields:
fields[f.name] = typemap.get(f.type, "TEXT")
return fields
def create_table_statement(table_name, fields):
defs = ", ".join(['"%s" %s' % (fname, ftype) for (fname, ftype) in fields.items()])
sql = 'create table "%s" (%s)' % (table_name, defs)
return sql
def insert_table_statement(table_name, fields):
refs = ", ".join([":" + f for f in fields.keys()])
sql = 'insert into "%s" values (%s)' % (table_name, refs)
return sql
def copy_table(cursor, table):
"""Add a dBASE table to an open SQLite database."""
cursor.execute("drop table if exists %s" % table.name)
fields = get_fields(table)
sql = create_table_statement(table.name, fields)
cursor.execute(sql)
sql = insert_table_statement(table.name, fields)
for rec in table:
cursor.execute(sql, list(rec.values()))
def main():
output_file = "himalayan_database.sqlite"
tables = ["exped", "members", "peaks", "refer"]
conn = sqlite3.connect(output_file)
cursor = conn.cursor()
for table_name in tables:
table_file = f"download/Himalayan Database/HIMDATA/{table_name}.DBF"
dbf_table = DBF(
table_file, lowernames=True, encoding=None, char_decode_errors="strict"
)
copy_table(cursor, dbf_table)
conn.commit()
if __name__ == "__main__":
main()
The database has four tables:
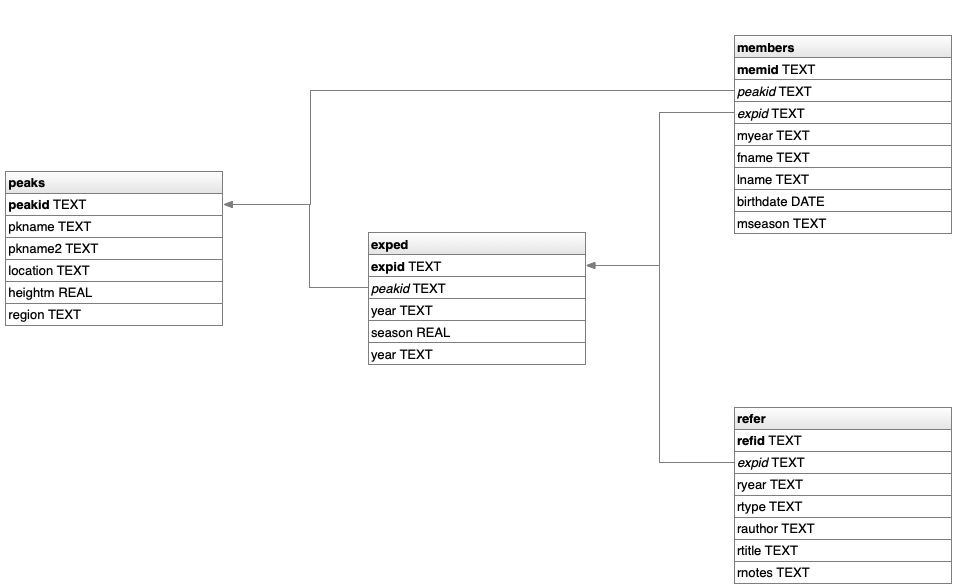
The peaks table has one record for each mountaineering peak of Nepal.
The exped table has one record describing each of the climbing expeditions.
The members table describes each of the members on the climbing team and hired personnel who were significantly involved in the expedition, one record for each member.
The refer table describes the literature references for each expedition, primarily major books, journal and magazine articles, and website links, one record for each reference.
You can now use DB Browser for SQLite to inspect the data. Appendix J: SQL Searches of the Himalayan Database documentation provides ideas for interesting queries on the data (in the FoxPro SQL dialect). In a follow-up blog post I am going to describe the database schema and field contents in more detail and also show some insights into historic Himalayan expeditions.