#PYTHON

Blue Yonder at PyCon.DE 2023
It's been now 10 years ago when Blue Yonder started the first sponsoring of a python conference at Europython Florence. Since then we have been either sponsoring and/or organizing at least one python event per year. Read More


Beautiful Leaflet Markers with Folium and Font Awesome
TIL how to use fontawesome markers with folium. Read More
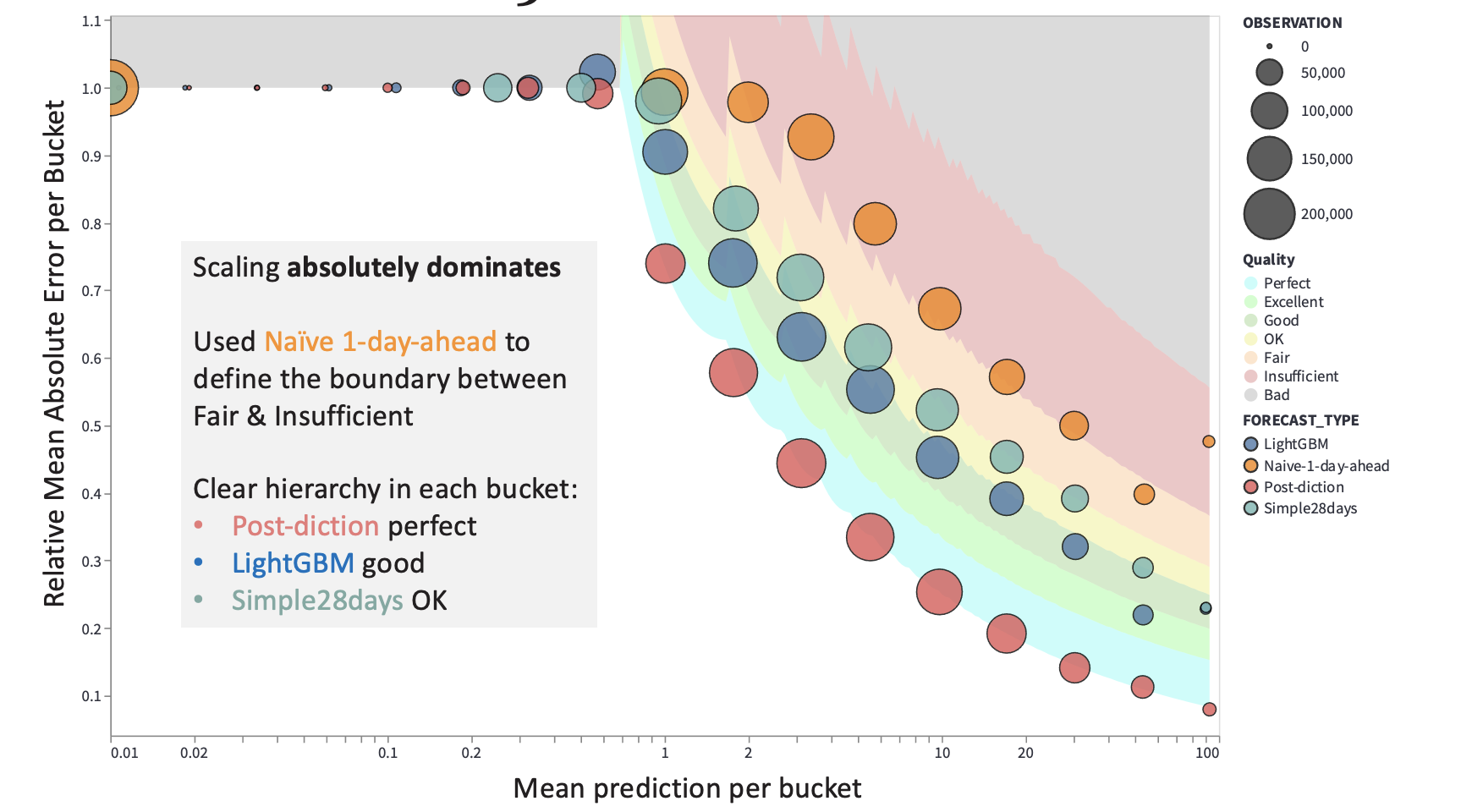

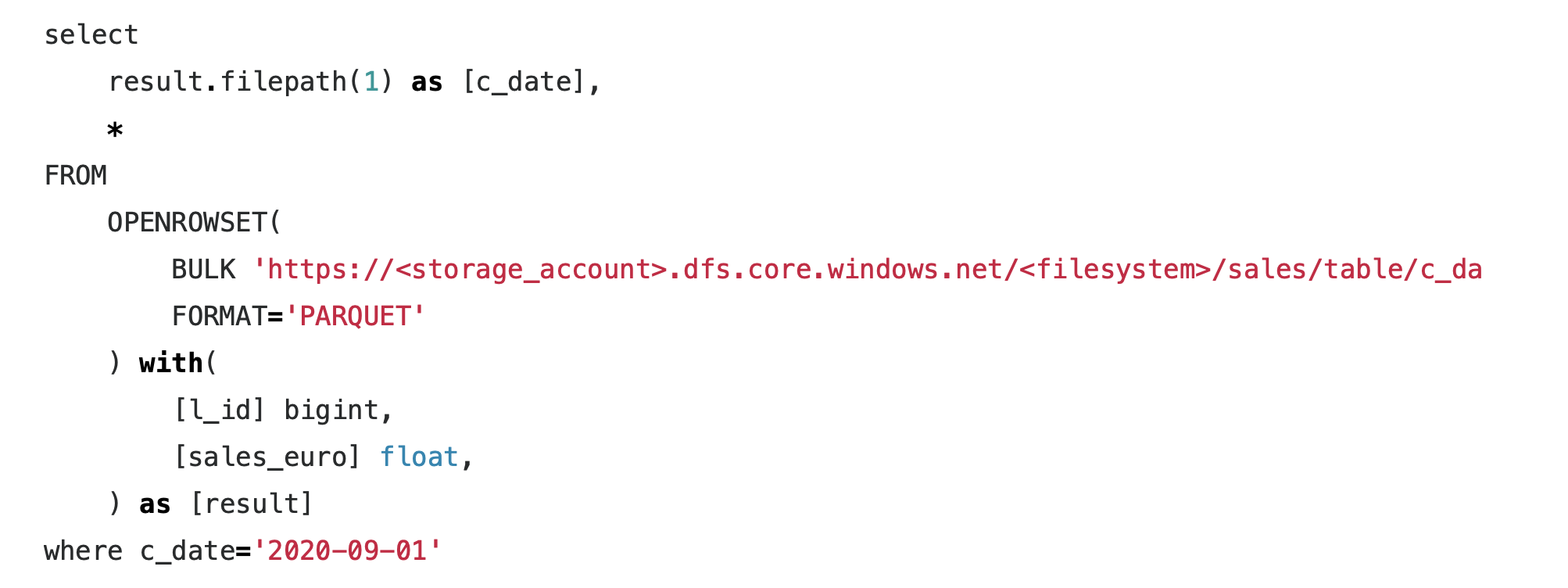

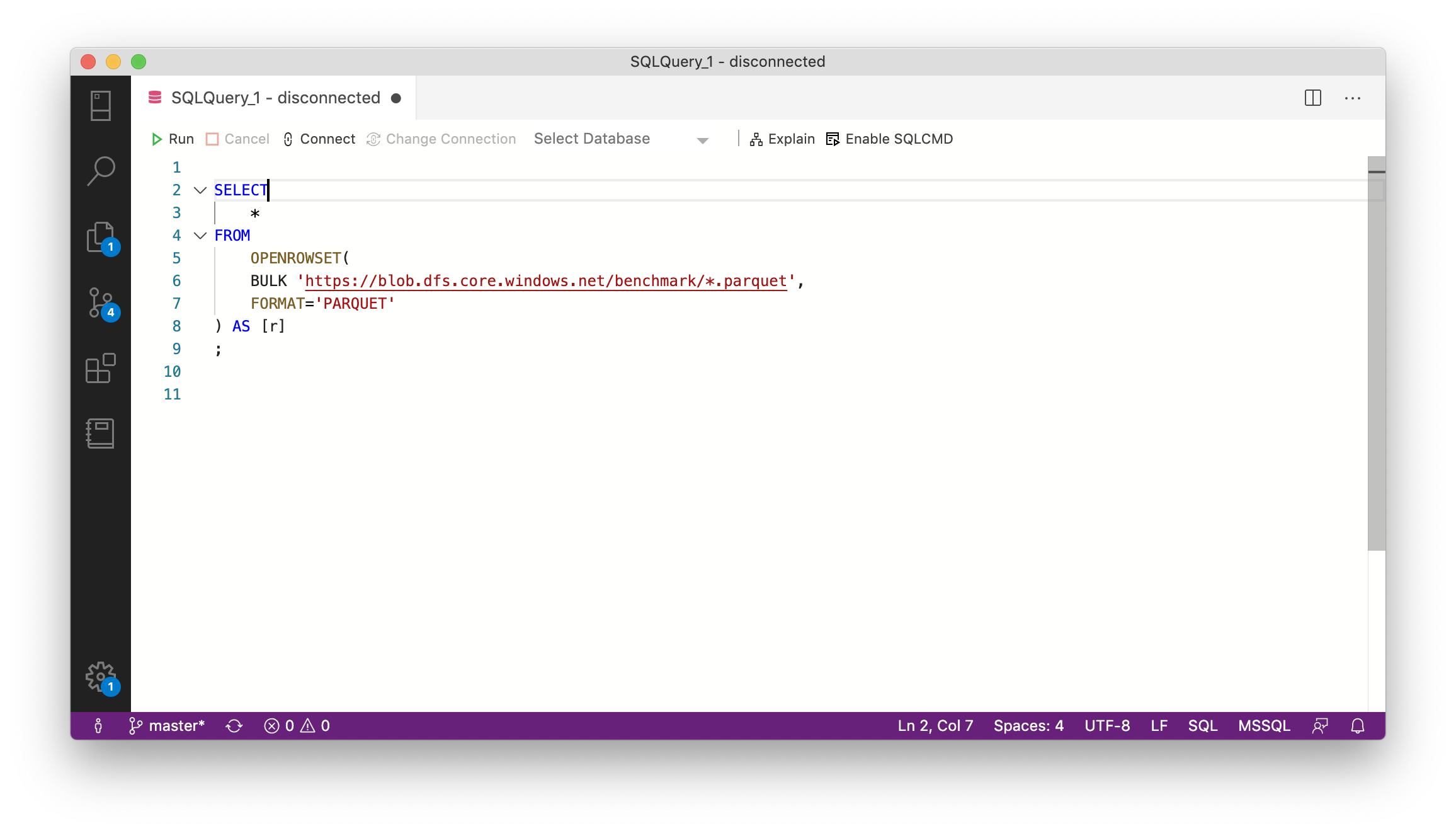
Azure Data Explorer and Parquet Files in Azure Blob Storage
Last summer Microsoft has rebranded the Azure Kusto Query engine as Azure Data Explorer. While it does not support fully elastic scaling, it at least allows to scale up and out a cluster via an API or the Azure portal to adapt to different workloads. It also offers parquet support out of the box which made me spend some time to look into it. Read More
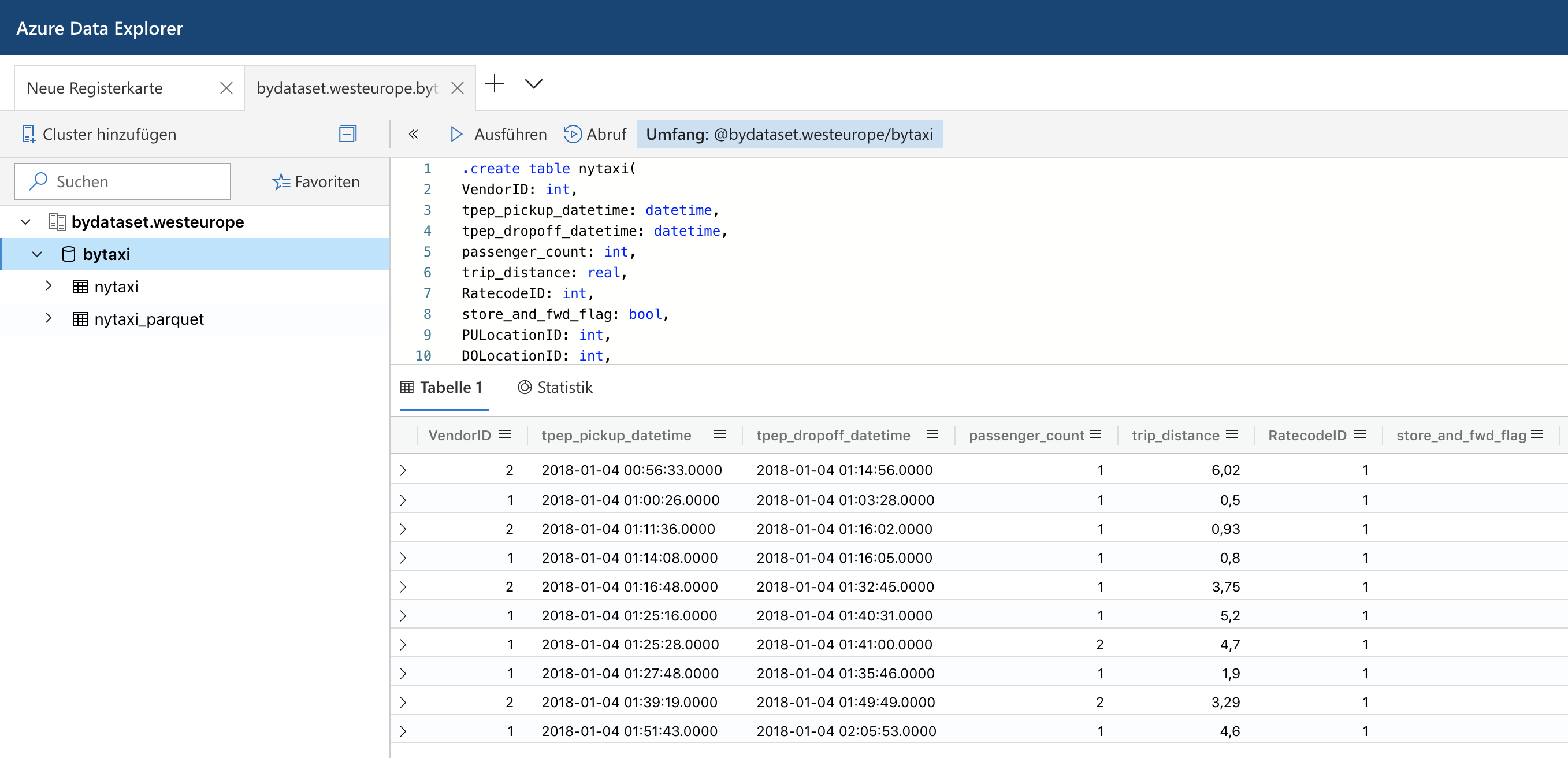
Understanding Predicate Pushdown at the Row-Group Level in Parquet with PyArrow and Python
Apache Parquet is a columnar file format to work with gigabytes of data. Reading and writing parquet files is efficiently exposed to python with pyarrow. Additional statistics allow clients to use predicate pushdown to only read subsets of data to reduce I/O. Organizing data by column allows for better compression, as data is more homogeneous. Better compression also reduces the bandwidth required to read the input. Read More


Karlsruhe Python Meetup at Blue Yonder
Python Meetup with two talks about python usage in a data science environment and the different stages of a python package in this environment. Read More

JDA ICON — Enabler of AI: Overview of an AI Architecture
JDA ICON 2019 was all about technology, APIs, AI (Artificial Intelligence) and ML (Machine Learning). Read More
PyCon.DE 2018
PyCon.DE 2018 is over. Second time in a row we organized it in ZKM Karlsruhe. Next year PyCon.DE will move to Berlin. Read More

EuroSciPy 2018 - Apache Parquet as a Columnar Storage for Large Datasets
Apache Parquet is an binary, efficient columnar data format that can be used for high performance data I/O in Pandas and Dask. Read More

EuroPython 2018 - Using pandas and Dask to work with large columnar datasets in Apache Parquet
Apache Parquet is an binary, efficient columnar data format that can be used for high performance data I/O in Pandas and Dask. Read More

Swiss Python Summit 2018 - 12-Factor Apps for Data Science with Python
Heroku distilled their principles to build modern cloud applications. These principles have influenced many of our design decisions at Blue Yonder to build a data science platform. Read More

How to Organize a PyCon.DE
Some notes on how to organize a conference like PyCon.DE Read More

PyCon.DE 2017 and PyData Karlsruhe
The venue setup @zkmkarlsruhe for #PyCon.DE 2017 and PyData Karlsruhe is done. We are ready for liftoff tomorrow. Read More

EuroPython 2017 - Infrastructure as Python Code - Run Your Services on Microsoft Azure
Using Infrastructure-as-Code principles with configuration through machine processable definition files in combination with the adoption of cloud computing provides faster feedback cycles in development/testing and less risk in deployment to production. Read More



PyConWeb 2017 Munich - Deploying Your Web Services on Microsoft Azure
This talk will give an overview on how to deploy web services on the Azure Cloud with different tools like Azure Resource Manager Templates, the Azure SDK for Python and the Azure module for Ansible and present best practices learned while moving a company into the Azure Cloud. Read More
PyCon.DE — 25–27 October 2017, Karlsruhe
The next PyCon.DE will be from 25-27th October 2017 at the ZKM - center for art and media in Karlsruhe/Germany. Read More


EuroPython 2014 - Log Everything with Logstash and Elasticsearch
When your application grows beyond one machine you need a central space to log, monitor and analyze what is going on. Logstash and elasticsearch store your logs in a structured way. Kibana is a web fronted to search and aggregate your logs. Read More

Go for Python Hackers
There is a resurgence of native-compiled programming languages going on. Some of this work is in response to Python; we're now part of The Establishment against which newcomers are measured. Greg Ward gives an overview of Go, a recent native-compiled language, and how it relates to Python. Read More

Atom Feed for Google Reader Liked Items
This post shows a simple Python solution: use httplib2 and ClientLogin to request a Google auth token, then call the likes Atom feed with an Authorization header to dump your liked items. The example code is minimal and can be adapted to fetch other private feeds such as private folders.' Read More
Python SocialGraph 0.2.3
python-socialgraph 0.2.3 has been released — grab the source from GitHub or the release package on PyPI. The library is a simple Python wrapper around the Google Social Graph API, making it easy to query and parse public connections between people and sites on the web for use in Python applications. Read More