Posted on
August 4, 2015
in
python ·
pydata ·
spark ·
conference ·
talk
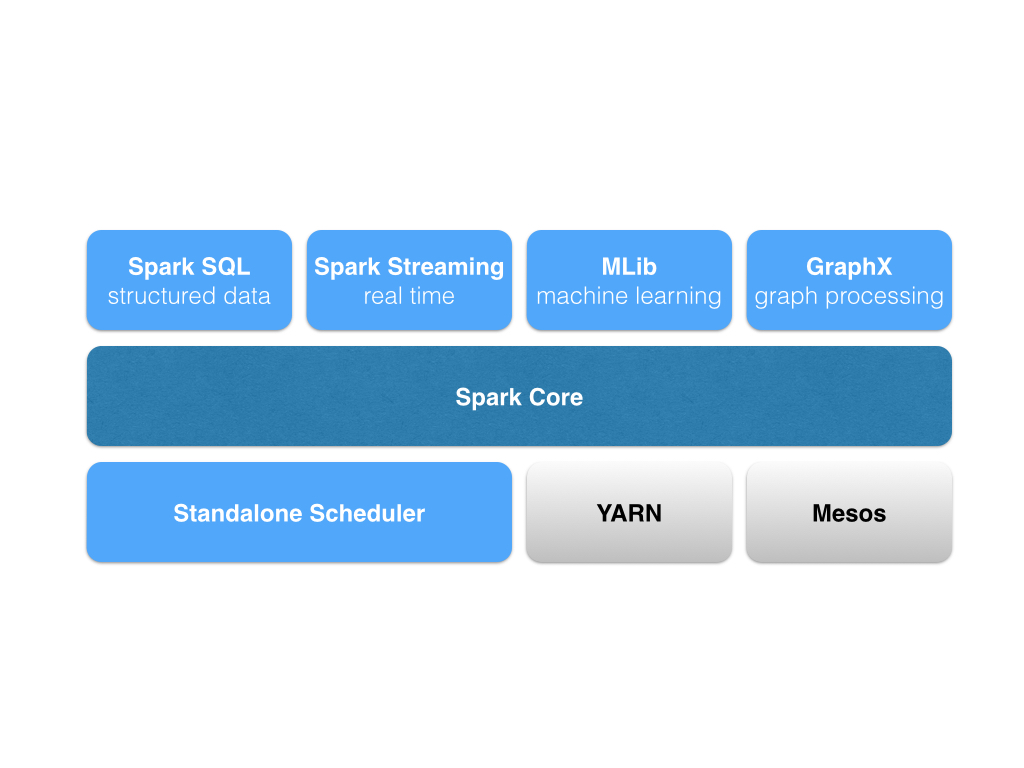
Apache Spark is a computational engine for large-scale data processing.
PySpark exposes the Spark programming model to Python. It defines an API
for Resilient Distributed Datasets (RDDs) and the DataFrame API.
Read More