#PYDATA
Beautiful Leaflet Markers with Folium and Font Awesome
TIL how to use fontawesome markers with folium. Read More

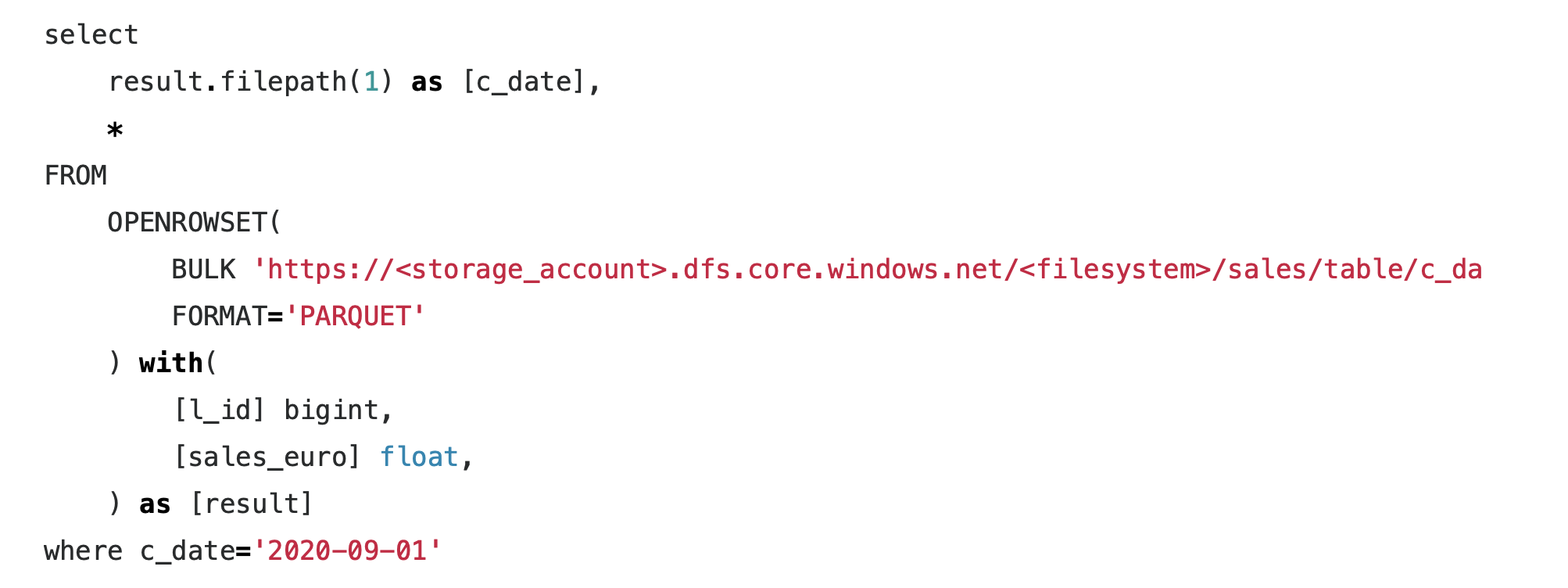

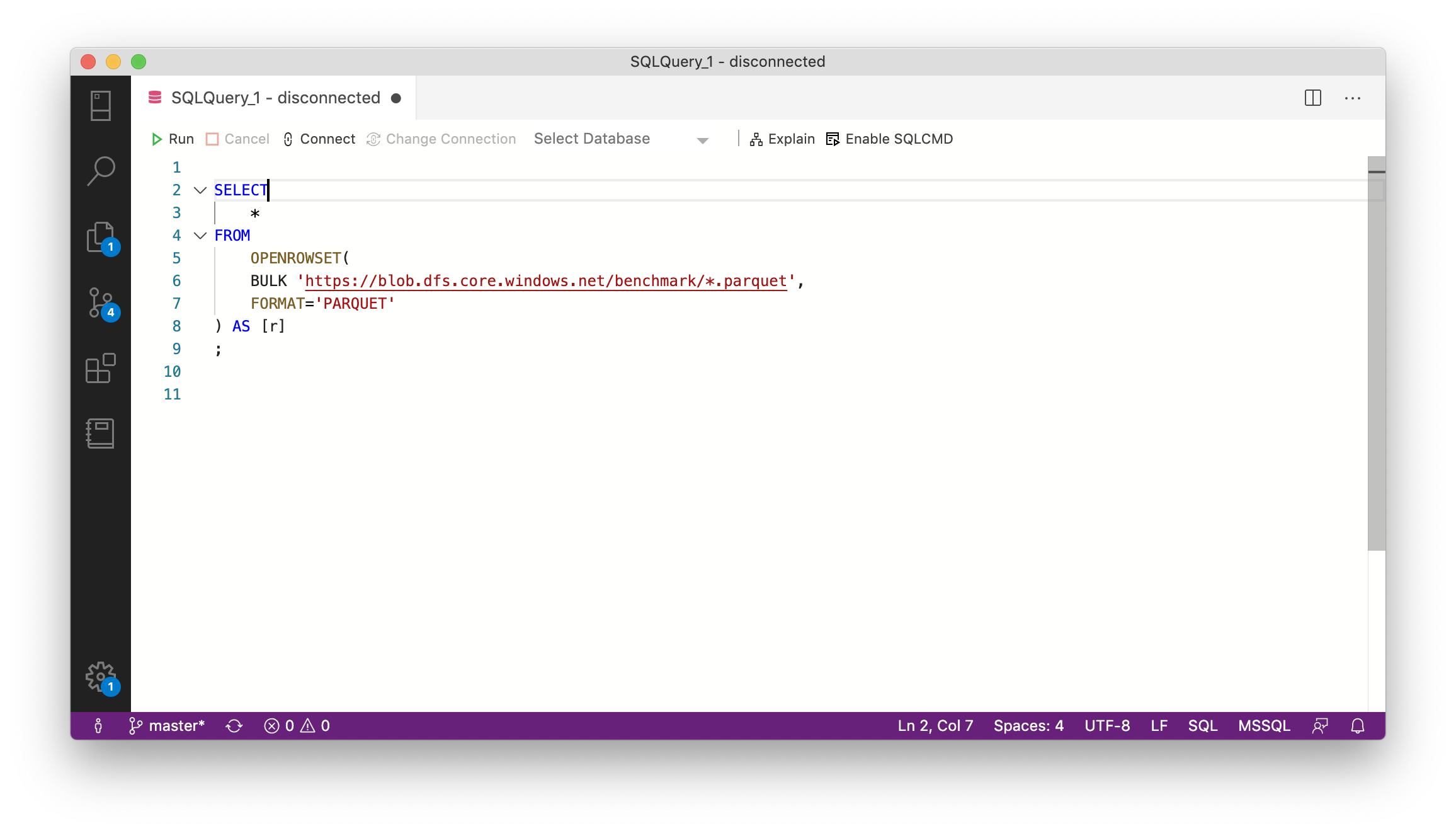
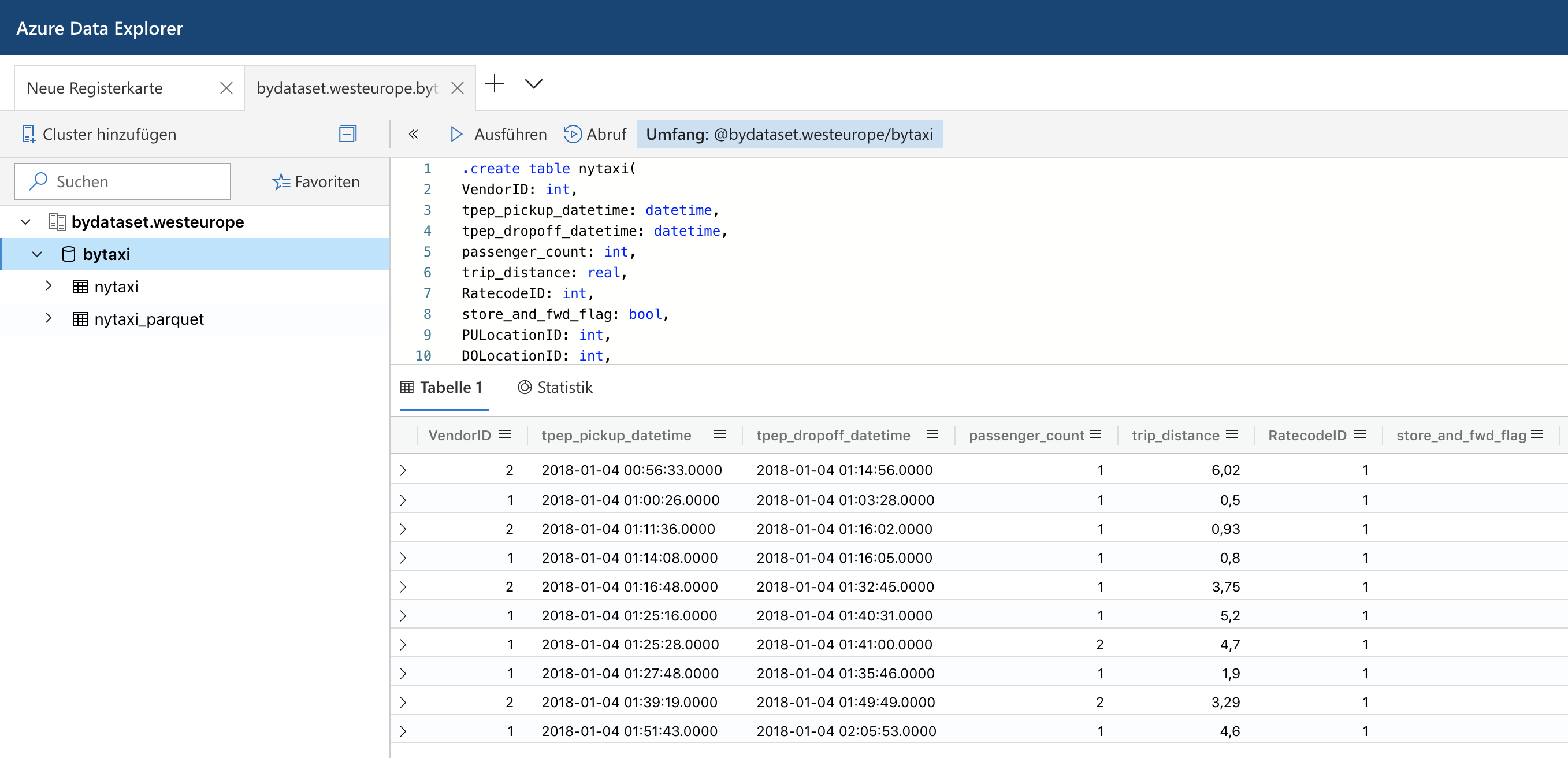
Azure Data Explorer and Parquet Files in Azure Blob Storage
Last summer Microsoft has rebranded the Azure Kusto Query engine as Azure Data Explorer. While it does not support fully elastic scaling, it at least allows to scale up and out a cluster via an API or the Azure portal to adapt to different workloads. It also offers parquet support out of the box which made me spend some time to look into it. Read More
Understanding Predicate Pushdown at the Row-Group Level in Parquet with PyArrow and Python
Apache Parquet is a columnar file format to work with gigabytes of data. Reading and writing parquet files is efficiently exposed to python with pyarrow. Additional statistics allow clients to use predicate pushdown to only read subsets of data to reduce I/O. Organizing data by column allows for better compression, as data is more homogeneous. Better compression also reduces the bandwidth required to read the input. Read More